What Salesforce Data 360 Is Not (and Why These Boundaries Matter)
Salesforce Data 360 is a term that quickly sparks debate — largely because many of us instinctively try to file it into familiar categories: a CDP, a data lake, an MDM platform, reverse ETL, or even something that competes with Snowflake, Databricks, or BigQuery. That reflex is understandable. But it’s also the fastest route to mis-scoping a project.
This article is a practical guide to building the right mental model by flipping the question: instead of starting with “what Salesforce Data 360 is,” we start with what it is not — and why. Getting these boundaries straight before you design Salesforce Data 360 (sometimes branded in the ecosystem as Salesforce Data Cloud) into your system landscape is one of the strongest predictors of success. The wrong mental model leads to the wrong expectations, the wrong implementation patterns, and often unnecessary cost.
At the core of the topic is a simple premise: business outcomes increasingly depend on data, but data only creates value in operations when two things are true. First, it must be connected and accessible across systems. Second — and more importantly — it must come with context: relationships, meaning, and identity links that make the data decision-ready. In an AI-driven world, context is the difference between automation you can trust and automation you can’t.
Salesforce Data 360 Is Not a Data Lake, Data Warehouse, or Lakehouse
A data lake, data warehouse, or lakehouse exists to ingest massive volumes, run complex transformations, support analytics at scale, and serve enterprise-wide reporting. Platforms like Snowflake, Databricks, and BigQuery are designed for heavy compute, modelling, large joins, and broad cross-domain governance.
Salesforce Data 360 is not trying to replace that. Its “gravity” is not analytics-first engineering work: it’s making customer-domain data usable inside Salesforce operations. A helpful boundary looks like this:
- Snowflake/Databricks/BigQuery: build and curate trusted data products (storage, transformation, analytics).
- Salesforce Data 360: make those data products usable in Salesforce processes without forcing Salesforce to become a data platform.
This distinction matters because Salesforce is a transactional platform. Trying to turn Salesforce into your data lake/warehouse creates CRM bloat, performance issues, and governance complexity. Data 360 is designed to avoid that trap by focusing on operational use cases and customer-domain context.
Salesforce Data 360 Is Not an Enterprise-Wide “Single Source of Truth”
Enterprise data programs often aim for a cross-domain “single source of truth” spanning finance, operations, HR, supply chain, marketing, and customer. Salesforce Data 360 is intentionally narrower: it focuses on data that is relevant to Customer 360 outcomes and customer-facing operations.
In practice, this means not every dataset belongs in Data 360. A general ledger is the classic example: it can be critical for finance and audit, but it is typically not needed to drive frontline customer interactions in sales or service. Data 360 is selective by design — if the data doesn’t help drive action in customer-facing workflows, bringing it in often adds cost without value.
Salesforce Data 360 Is Not an ETL/ELT Transformation Engine
If your expectation is that Salesforce Data 360 replaces your ETL/ELT stack, you’ll likely scope it incorrectly. Heavy transformation: pipelines, complex joins, large-scale modelling belongs where compute is optimized and where data engineering practices already live: your lakehouse/warehouse stack (Snowflake, Databricks, BigQuery, etc.).
Data 360 is better understood as the layer that consumes curated outputs and makes them operationally usable in Salesforce aligning them to customer-domain structures, identity, and relationships so they behave predictably inside Salesforce processes.
Salesforce Data 360 Is Not Reverse ETL (and Not “Push Everything Into Salesforce”)
Reverse ETL is a known pattern: curate data in your warehouse, then push subsets into operational tools like Salesforce. It can work, but it often becomes a point-to-point integration strategy at scale with many pipelines per use case, schema drift, duplicated logic, and brittle dependencies.
More importantly, reverse ETL can encourage treating Salesforce as a destination store for operationalized datasets. That’s how you get:
- CRM bloat (custom object and field sprawl)
- Performance challenges and higher storage costs
- Governance complexity and duplicated definitions
- Fragile pipelines and ongoing maintenance overhead
Salesforce Data 360 is positioned as a different architectural approach: reduce the number of repeated point integrations by creating a specialized customer-domain activation layer that is natively aligned with Salesforce experiences.
Salesforce Data 360 Is Not Middleware / ESB (and Does Not Replace MuleSoft)
This is a common confusion: data enrichment versus application orchestration.
MuleSoft (and other middleware/ESB tools) orchestrate cross-system processes: moving messages, coordinating APIs, handling retries, and managing transactional flows across applications (e.g., Salesforce → ERP → billing). Salesforce Data 360 does not replace that role.
Instead, Data 360 enriches Salesforce with customer-domain context so that Salesforce processes, users, and AI can make better decisions. Put simply:
- MuleSoft: moves transactions between systems.
- Salesforce Data 360: brings customer context into Salesforce operations.
Salesforce Data 360 Is Not an MDM Solution
MDM (Master Data Management) is typically match-and-merge, stewardship, golden record governance, data quality processes, and distribution of mastered identifiers back to source systems. Salesforce Data 360 is not designed to replace that type of enterprise-wide master data governance program.
Data 360 is closer to identity stitching in the customer domain: linking identifiers across systems so Salesforce can understand that multiple keys refer to the same person or account and then use the associated engagement and relationship context in operational decisions. MDM and Data 360 can coexist, they solve different problems at different layers.
Salesforce Data 360 Is Not “Just Another CDP”
Because Data 360 touches identity and activation, it is often labelled as a CDP (Customer Data Platform) or “CDP rebranded.” There is overlap in intent: CDPs are about connecting data, resolving identity, and activating audiences. But many CDP implementations have historically been marketing-centric, and organizations still end up rebuilding point-to-point integrations to make CDP outputs usable for sales and service in a consistent way.
Salesforce Data 360 emphasizes consistency across Salesforce touchpoints: sales, service, marketing, and increasingly AI-driven experiences as a native customer-domain activation layer rather than a marketing-adjacent activation silo. If your mental model is “it’s only a CDP for marketing,” you’ll miss the broader platform intent.
Salesforce Data 360 Is Not Only for Enterprises with Hundreds of Data Sources
Another misconception is that Salesforce Data 360 is only relevant if you’re an enterprise with “750+ sources.” In reality, complexity shows up quickly with far fewer systems. The real driver is not the number of sources. It’s the number of operational decisions you need to make reliably across systems inside Salesforce.
Even a common landscape: Salesforce + ERP + billing, or Salesforce + marketing + web behavior, can create identity gaps, inconsistent definitions, and context problems that block automation and reduce trust in AI-driven workflows. Data 360 is best approached use-case first: start with one operational use case where better data context improves outcomes, prove value, then expand.
Why These “Not’s” Matter: Salesforce-Native Operationalization
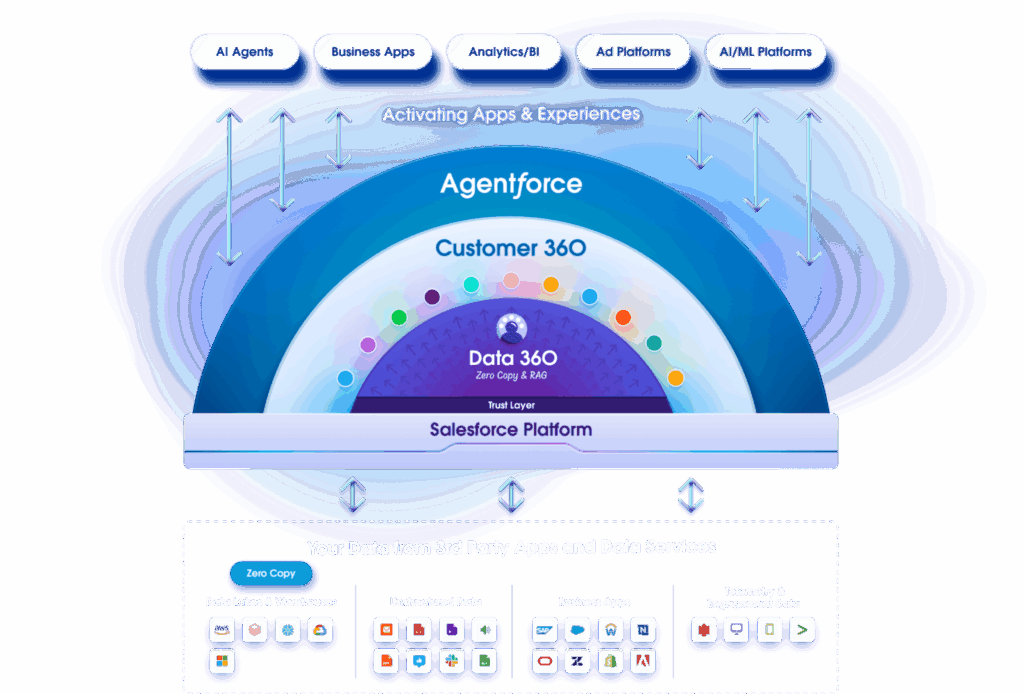
If you compress all these boundaries into one statement, it’s this: Salesforce Data 360 is a specialized customer-domain activation layer that is natively aligned with Salesforce applications, designed to make trusted, external customer data decision-ready inside Salesforce processes without forcing Salesforce to become your data platform, your MDM hub, or your integration backbone.
Once you adopt that mental model, the architecture choices get simpler. Data platforms like Snowflake, Databricks, and BigQuery remain the best place to engineer and govern data products at scale. MuleSoft remains the best tool for orchestration. MDM remains the discipline for mastering. And Salesforce Data 360 becomes the layer that makes customer data usable where it matters most: in Salesforce operations, automation, and AI-enabled customer experiences.