So, you have started using Salesforce Marketing Cloud, and spotted that little menu, listing Email Recommendations and Web Recommendations. But what is this all about, and how can you come around to build a useful implementation? One of my favourite use cases for this, is lead scoring.
Introduction
You can use Einstein Email Recommendations to observe customer behavior, build preference profiles, and deliver the next-best content or product. You can also refine recommendations to match your business rules. Recommendation content surfaces in placeholders for recommendations on your website.
Email recommendations are delivered as a pre-built image and link pair and are activated when a user engages with the email. We refer to email recommendations as engagement recommendations, meaning the logic and scenarios are processed immediately before they see the recommendation.
The image in the recommendation is based on an HTML template that is used to style what one recommendation would look like. Each product or content recommendation is generated ahead of time and stored to ensure that the image is instantly available. By pre-processing displays and logic for each product or content recommendation, the most up-to-date recommendation is delivered without sacrificing performance when a subscriber engages with the email.
Did you know?
When you add recommendations to your email, the logic behind them will not be evaluated at send-time (e.g. if they were using Ampscript logic), but during open-time.
This allows you to provide fully up-to-date recommendations, based on most recent behaviour, but also to exclude products which might have been available at the time of email send, but were sold out prior to the email being opened.
You can also create Einstein Web Recommendations for using on your website, where the products will be displayed in HTML, or provided in a JSON feed. Another difference between having the recommendations in emails vs. on the website is, the need to link the collected product views to an identifier known at sendtime (like a hashed email address). This is not needed in web recommendations, as they are mainly cookie based.
Prerequisites
Do keep in mind, a product or content catalogue is required before you can start collecting data and showing predictions. It doesn’t need to be complete, but at least a baseline catalogue with e.g. 10 items needs to be uploaded. The sooner you start collecting data, the better – as this will improve the quality of the recommendations shown. If you collect an sku or item not in catalogue, this view will not be stored in a data extension. Ongoing updates of the catalogue can happen by either of these two methods:
- Daily Flat-File Upload. The daily flat file upload is added to an FTP account or publicly accessible web URL and imported into Einstein Recommendations at the same time daily. A full upload of all products and a daily delta file is supported.
- Streaming Updates. The Streaming Update option adds and updates products and content through another snippet of Server-Side JavaScript. All data must be available in the web layer sent in each call.
- Be aware that streaming updates today are different to what they were few years ago. It is no longer possible to do this simply via client side javascript.
The updated method will be requiring you to POST a JSON payload to a specific URL:
https://MID.collect.igodigital.com/c2/MID/update_item_secure.jsonThis expects to receive the item details, along with the API key, which you can find under Admin > Implementation, for the Einstein Recommendations.
A sample payload looks like this:
{
"api_key": "INSERT_YOUR_API_KEY",
"payload": {
"item": "INSERT_ITEM",
"unique_id": "INSERT_UNIQUE_ITEM_ID",
"item_type": "INSERT_ITEM_TYPE",
"name": "INSERT_ITEM_NAME_OR_TITLE",
"url" : "INSERT_ITEM_URL",
"INSERT_ATTRIBUTE_NAME": "INSERT_ATTRIBUTE_VALUE"
}
}Replace the ‘INSERT_’ values with the dynamic code to get the appropriate value for the item. Acceptable values for ‘item_type’ are ‘content’, ‘product’, or ‘banner’. If the value is not specified, or the value provided is not recognized, it will default to ‘content’.
Once your catalogue is ready, you can start adding the tracking script:
<script type="text/javascript" src="https://MID.collect.igodigital.com/collect.js"> </script>
<script type="text/javascript">
_etmc.push(["setOrgId", "MID"]);
_etmc.push(["trackPageView", { "item" : "INSERT_PRODUCT_CODE" }]);
</script>Remember to put your actual business unit ID value in the MID placeholder, and a unique product ID in the INSERT_PRODUCT_CODE placeholder.
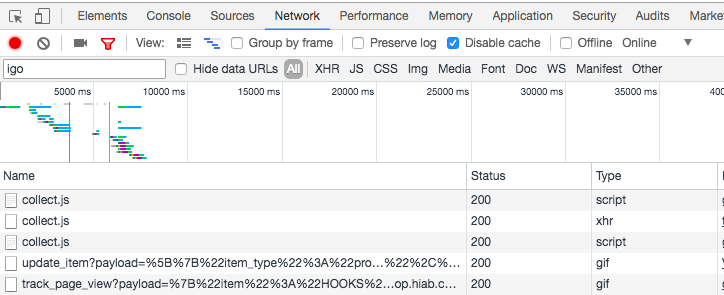
If you believe your Collect Code is implemented correctly, you can verify it using Chrome Developer Tools. After opening the tools, go to Network tab, and put igo in the search box. This will show you any calls being made to Collect Code/Marketing Cloud. See an example of this below:
Data integration
One of my favourite features here, is the ability to populate a number of data extensions based on browsing behaviour.
Under Status in Einstein Recommendation, you can click on the gear symbol, and choose Data Extension Settings:
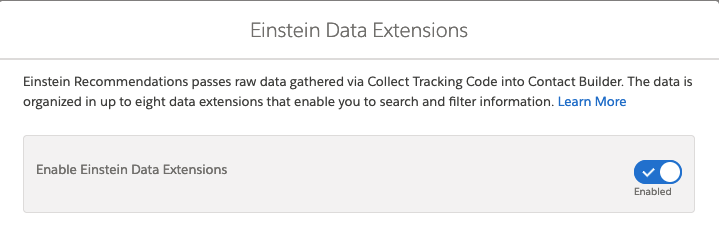
This will open a modal, where you can enable the Data Extension Integration:
This might show you few warnings, and depending on the nature of the warnings, you might want to wait 24 hours or so, before validating records coming into your data extensions:

Once successfully configured, you can find the appropriate
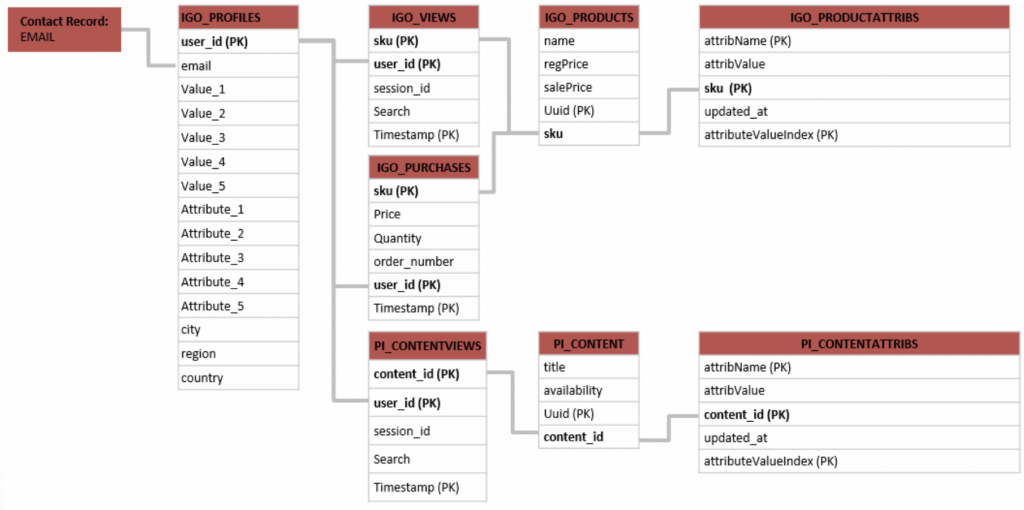
- IGO_PROFILES: Mapping between the native uuid of W&MA and whatever identifier you provide in
setUserInfocall. The provided identifier will always reside in the email field. The customer’s profile will also store what the algorithm has determined are the top five attributes for which the customer has the highest affinity. This top five is updated at the end of every user session. - IGO_VIEWS: Stores information on when specific products were viewed
- IGO_PURCHASES: Stores information on when specific products were purchased
- IGO_PRODUCTS: Contains basic information on products
- IGO_PRODUCTATTRIBS: Full metadata on products, derived from catalogue import
- PI_CONTENTVIEWS: Stores information on when specific articles/non-product pages were viewed
- PI_CONTENT: Contains basic information on articles
- PI_CONTENTATTRIBS: Full metadata on articles, derived from catalogue import
We have the ability to see all data coming in to our data extensions, available for processing. In IGO_PROFILES, we find the identifying attribute (in email column) and a number of calculated affinities can be seen (In Value_X and Attribute_X columns). These are based on internal calculations in Einstein Recommendations, and cannot be altered – hence we have no control which metadata will be selected for affinity calculation. You would think these can be added through setUserInfo call, which unfortunately is not the case.
Do not use email address, but rather a hashed identifier when using setUserInfo call, as providing PII in plain text on a website is not recommended.
It is a very ”quick and dirty” way of segmenting consumers, and whenthis DE gets joined with a DE containing opted-in consumers, we can produce a sendable DE with an audience, with a specific affinity.
Having detailed information on every single product visit (IGO_VIEWS) allows us – theoretically, to build more complex segments using SQL to lookup e.g. categories in IGO_PRODUCTATTRIBS. However, the volume of the records can make it impractical, and at times close to impossible.
These data extensions can be easily used in Automation Studio Queries, to build audiences based on e.g. browsed products. The diagram above shows the relationships between the individual data extensions. And since the *ATTRIBS data extensions are working by storing name value pairs, the query to find “emails” of users visiting content where size=Large, would be:
select email from IGO_PROFILES prof
where prof.user_id in
(
select user_id from PI_CONTENTVIEWS cv
inner join PI_CONTENTATTRIBS ca
on cv.content_id = ca.content_id
where ca.AttribName = 'size'
and ca.AttribValue = 'Large'
)And remember, email is NOT email, but the value you have passed in the setUserInfo call in your tracking code.
If you want to dive deeper into the more technical aspects of Einstein Recommendations, I can highly recommend this very thorough overview made by Jörn Berkefeldt. It is packed with code examples and explains every aspect of both tracking as well as recommendations. One of my favorite parts is his code helping you embed web recommendations from JSON feed.